From Aspiring to Artful: The Journey of Learning Machine Learning Engineering



Machine Learning has become one of the hottest buzzwords in the tech industry in recent years, with job titles such as “ML Engineer” and “Data Scientist” becoming increasingly common these days. However, as someone who has been studying ML for the past two years, I’ve come to realize that these titles don’t quite capture the true essence of what it means to work in the field of Machine Learning.
My journey in Machine Learning began with Andrew Ng’s course on Neural Networks. I quickly became engrossed in creating ML algorithms from scratch using NumPy. However, as I delved deeper into the field, I realized that I had been overlooking the broader implications of my work. The real world demands high-quality work and effective communication with stakeholders. To excel, one must have a deep understanding of the business problems that ML is intended to solve and collaborate with various departments to ensure the final product meets everyone’s needs. Working in Machine Learning is both rewarding and challenging, and by constantly pushing the boundaries, one can continue to innovate in this exciting industry.
The deep learning party is on Twitter

Photo by Roman Martyniuk on Unsplash
Twitter was a game-changer for me in terms of my understanding of ML Engineering. By following leading experts in the field, I was able to rediscover the whole paradigm once again. I discovered two major schools of thought: those focused on “core” ML research, constantly disrupting different parts of the industry, and those focused on building and scaling ML-powered applications to millions of users. I realized I didn’t belong to either group yet, so I decided to start from scratch and focus on the engineering perspectives of ML. After immersing myself in this second school of thought and following experts, blogs, and content, I finally started to gain a better understanding of what engineering in ML truly means. Let’s break it down further. You can check out my following lists and can follow folks you like.
No one cares about your model
Photo by Jeswin Thomas on Unsplash
Let’s face it: when it comes to machine learning, it’s easy to get caught up in the latest research and techniques. But sometimes, it’s important to step back and ask yourself some key questions. For example, if you’re working on a credit card fraud detection project, what is the company’s primary business goal? What are the business KPIs? What are the possible cost and time estimations for deployment? And most importantly, where will the model be used and what are the expectations?
While it’s tempting to get excited about the latest research and propose an ultra-impressive model (for example a transformer based reinforcement learning agent for fraud detection), the truth is that your colleagues and boss may not share your enthusiasm. They may be more interested in a simple logistic regression model that can be implemented quickly and improved iteratively. What matters most is creating a working solution (the overall system where the ML model is just a tiny tiny part of it) that meets the requirements and aligns with the company’s goals. So even if the model is giving an accuracy of just 74% but checking in almost all the requirements in the list, it is far more acceptable than just wasting months and building nothing due to over complexity.
The secret behind your “cool” models lies in clean data

Behind every “cool” model, there’s a dirty little secret — clean data. That’s right. Neural networks may seem like magic, but they’re just mathematical models that detect patterns in your data. The more complex your model is, the better it will be at finding these patterns. But here’s the catch — if your data is garbage, your model will be garbage too. But let’s say you have top-notch data — what then? Well, even a simple hyperparameter-tuned model can also work wonders.
Now, let’s talk about a real-world scenario. Say you’re working on a credit card fraud detection system. You’ve trained your model on data from 2013 to 2018 and it’s performing beautifully. Your boss is pleased, and your coworkers are impressed. But then, something happens — a new type of fraud pattern emerges in the transactions. Your model can’t handle it because it wasn’t trained on this data. And this is one of the reasons why companies are always collecting data. To stay ahead of the curve and retrain their models when new patterns emerge. So, the moral of the story is this — if you want to build a successful model, then it is very much necessary to build better data pipelines so that it can create better features to finally come up with better predictions after the training.
As machine learning practitioners, we often overlook the importance of data. Real-world data is not just a set of CSV files; it’s the result of extensive engineering efforts, including backend development, data collection, and ETL practices. We must have a understanding of the data and its pipelines to create effective machine-learning solutions.
Imagine a scenario
Suppose you are working at a fintech company that wants to develop a credit card fraud detection system. Your company’s business goal is to minimize financial losses due to fraud, which is the primary reason for developing this system. To achieve this goal, your company needs to build an end-to-end ML pipeline that involves various stages such as data collection, data preprocessing, feature engineering, model training, model validation, model deployment, and monitoring. You do not need to understand everything here, just take the inner essence here.
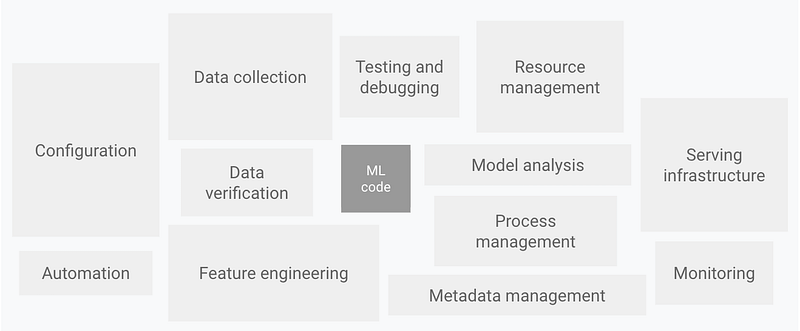
Image courtesy: Google Cloud
The first stage is data collection, which involves acquiring data from various sources, such as credit card transactions, customer profiles, and historical fraud records. The data may be available in different formats, such as CSV, JSON, or SQL databases, and may be stored on-premises or in the cloud. The data collection stage also involves defining the data schema, ensuring data privacy and security, and handling missing or corrupted data.
The second stage is data preprocessing, which involves cleaning, transforming, and normalizing the data for further analysis. This stage also involves handling categorical data, numerical data, and text data using various techniques such as one-hot encoding, normalization, and tokenization etc (This blog does not intend to cover details for each of these methods) . Data preprocessing is a crucial stage as it helps to remove noise and bias from the data and prepares it for feature engineering.
The third stage is feature engineering, which involves selecting relevant features that can help to improve the predictive power of the ML model. This stage involves domain knowledge and creativity, as well as statistical and mathematical techniques such as correlation analysis, PCA, and clustering. The feature engineering we generally do is not only meant to stay behind some “untitled” jupyter notebooks. Those “good” features taken out from the process of feature engineering also involve creating a feature store, which is a centralized repository of reusable features that can be accessed by multiple ML models.
The fourth stage (a familiar domain for most of us) is model training, which involves selecting an appropriate algorithm and tuning its hyperparameters to maximize the model’s accuracy and generalization. Model training also involves choosing an appropriate evaluation metric, such as precision, recall, or F1-score, and validating the model’s performance using various techniques such as cross-validation. In this stage, ML Engineers and data scientists mostly undergo rigorous experimentation and tracking to track the model’s performance and finally end up selecting the best model under some defined metrics (for example, Accuracy, precision, recall, and even other computation parameters like speed, hardware usage and sometimes other business metrics too)
The fifth stage of the ML lifecycle is model deployment, which involves integrating the trained ML model into a production environment. This production environment can be a web application, a streaming pipeline, or any other system that requires real-time predictions from the model. Model deployment is a critical step in the lifecycle as it determines the success of the model in the real world.
To deploy the ML model, it needs to be integrated with the backend system through the client-server architecture. Typically, the model is wrapped around a REST API that enables the backend to communicate with it using a request-response model. The REST API allows the backend system to send data to the model for prediction and receive the predicted results in real time.
To ensure smooth deployment, the ML model needs to be tested thoroughly to ensure it can handle the expected workload and deliver accurate predictions consistently. Additionally, proper monitoring and maintenance of the deployed model are crucial to ensure it continues to perform optimally in the production environment.
Even in all of these steps, you are very much like to collaborate with your colleagues. By using Git, you can keep track of changes to the codebase and collaborate with your team more efficiently. This allows you to avoid conflicts between different versions of the code and ensures that everyone is working on the same codebase. Using GitHub you can host all of those changes and work remotely.
This is not the end. Lots of things like infrastructure, monitoring, workflow automation, etc etc are also included. If you have heard about DevOps, then it is kinda the same thing. The only difference is that here we deal with continuous integrations and continuous deployment w.r.t changes done by the model and all the systems connected to it. In other words, MLOps.
In summary, all I wanted to convey here is, the machine learning we generally see should not be bounded under some bunch of “untitled” jupyter notebooks. There is a proper discipline that needs to be followed and maintained to reach a perfection saturation point. Until that, it’s all about iterating and building again and again. True engineering is something where we can connect cross-domain knowledge into a fully functional working system. The beauty lies in the process of learning and creating those systems from scratch.
Okay, enough now please give me a roadmap.
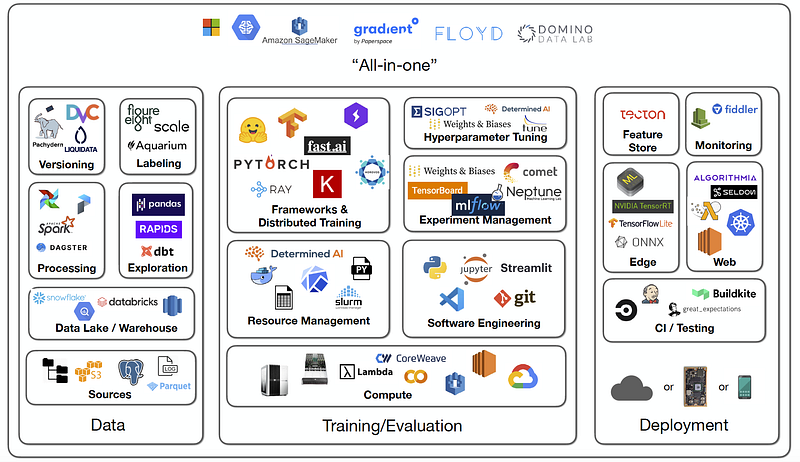
Image courtesy: Full stack deep learning
This is where you get wrong my friend. Lemme tell you there is no such roadmap. Even if I provide one, the vastness will kill all the enthusiasm. Let’s get real here. Nowadays being a T-shaped (someone who has a broad range of general knowledge in various areas of software development, combined with deep expertise in one or more specific areas) developer in Machine learning means, you need to have a grasp of how software engineering works. This means you need to know about backend systems (connecting backend to ml for data and ml to backend for returning prediction), a bit of fronted (yes it is required, and helpful to know at least one framework, otherwise where you are gonna show your end product of your initial MVP to your users ?), knowledge about software engineering best practices, git/GitHub and workflow management, knowledge about deploying (this includes serving backend APIs using docker/Kubernetes), know-how about cloud, and this list just goes on with technical jargons. So now if I just say that do this or that at week one and so and so, most of us will lose interest. And it is quite natural for people to forget things unless and until they will use them often. Then how to start?
Keep your foundations strong
When it comes to building any complex system, strong foundations are key. This is especially true in the field of machine learning. While it may be tempting to dive straight into building models, it’s important to have a solid understanding of the fundamentals that underpin these models. To begin with, a basic understanding of client-server architecture and networking models is essential. Additionally, a working knowledge of operating systems and basic data structures will be immensely helpful. This doesn’t mean you need to be an expert in every topic, but a firm grasp of the basics will go a long way. You should also have a good understanding of at least one programming language, as well as how to write code with it. Another critical foundation for machine learning is understanding how databases work, as ML is fundamentally about working with data. Finally, it’s important to have an understanding of some of the key concepts in ML, such as feature engineering techniques, basic statistics, and overfitting. These concepts will be critical when building applications around your models. While this is just scratching the surface of what’s needed to build successful ML applications, it’s a good starting point to ensure your foundations are strong.
Your every project is a product
Photo by Cova Software on Unsplash
Yeah, you heard that right. But for that do I need to spend time to get that idea? NOOOO. You can begin with simple projects like predicting heart disease or the Titanic survival rate, and then take it a step further by deploying it to a Streamlit app. Streamlit is a user-friendly framework that allows you to create interactive dashboards and playgrounds to serve your machine-learning models with just a few lines of code.
However, creating a Streamlit app is just the beginning. To make it more “real world,” you need to detach the front end from the backend and create APIs. By creating simple Flask or FastAPI API endpoints, you can connect the backend to a frontend like a React app.
Once you have your app running smoothly, you can take it to the next level by deploying it to a free cloud environment like Azure. Azure offers $100 in free credits for students who sign up with GitHub. By extending one simple project in this way, you can gain experience and learn how real-world machine learning-powered apps work.
Conclusion

Photo by Cristofer Maximilian on Unsplash
In conclusion, we have discussed the various stages of the machine learning deployment process, from data collection to model deployment, and highlighted the importance of understanding the end-to-end pipeline. It is essential to approach machine learning as an engineering discipline and be willing to learn new tools and technologies as needed. While it may be tempting to focus solely on machine learning algorithms, it is important to remember that real-world applications require a full-stack approach. As the field of machine learning continues to evolve, there may be fewer things that are strictly tech stack specific, and the ability to learn quickly and fearlessly will be crucial for success. By approaching machine learning with a broad and adaptable mindset, we can ensure that our projects are not just machine learning experiments, but real-world products that meet the needs of users and businesses alike.
In the coming posts, I will discuss more on the specifics of each of the lifecycle steps, also some underrated resources, which keep the potential to accelerate your upcoming journey of building ML systems.